
Your agent needs better judgement.
Evals tell you about the failures you already imagined. Production tells you the truth. Raindrop is the production improvement loop for agents, so you can see how your agent actually behaves and make it sharper every day.
that's the CTO of Speak, a language app with 15M learners
Teams already sharpening their agents


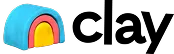



Bad judgement
fails silently.
When a normal API breaks, you get a 500 and a stack trace. When an agent exercises bad judgement, invents a refund policy, forgets what the user said three turns ago, loops on a tool, takes the long way around, nothing breaks. The status is 200. The JSON is valid. The customer just got bad advice.
Agent failures are semantic, not syntactic. The input space is infinite: arbitrary natural language, shifting models, new tools, custom instructions. A thousand test cases still won't cover what a real user says on day one.
You can't test judgement in a lab. You have to test it in the real world, across every conversation, and improve it on a loop. That's what Raindrop is for.
We were promised personal agents
The thing standing between us and agents that actually know us isn't a bigger model. A personal agent rests on four pillars, and judgement is the one that makes the other three usable. Memory without judgement is noise. Adaptability without judgement is mood swings. Prediction without judgement is spam.
Memory
Knowing who you are
Modern memory is RAG over every chat you’ve ever had: fast, and genuinely good. The catch is it remembers everything but doesn’t know when to use it. Recall without restraint is its own failure mode.
Judgement
Knowing its skills and limits
Judgement decides what to pull, when, and whether to ask first. A good tutor knows if you’re stuck on basic conjugations or ready for the subjunctive. Everything else depends on this.
Adaptability
Adjusting tone and behavior
Real conversations move from serious to playful, blunt to gentle. Rigid system prompts can’t. Adaptability is reading the turn, shifting tone, and noticing when it should stop and ask.
Prediction
Anticipating your needs
The part that’s mostly missing today. Our closest friends check in right before a launch or after a hard day. A real assistant should too, but only once it has earned the right.
From stumble to fix, on a loop.
Four moves take your agent from guessing to judgement. Raindrop runs all of them on your real production traffic, no eval suite required to get started.
See exactly where users stumble.
Stumbles are the quiet product failures, the moments a user has to do the work the agent should have done. The answer was polished but the next step was wrong. A long turn ended with a blank response. The agent retried the same tool instead of switching strategy. Nothing errored, but judgement slipped.
- Tool retry loop burned an entire turn
- Long generation ended with a blank answer
- Recovery flow pointed to the wrong page
Issues surface automatically.
Raindrop is the first automatic issue-detection system for agents. It reads every interaction and clusters silent failures into issues, hallucinations, loops, refusals, tool failures, before your users report them. Each issue links to the events that prove it, with model and tag breakdowns.
- Agent hallucinated a policy that does not exist
- Stuck in a 12-turn loop asking for the same info
- Tool call to the payments API failing silently
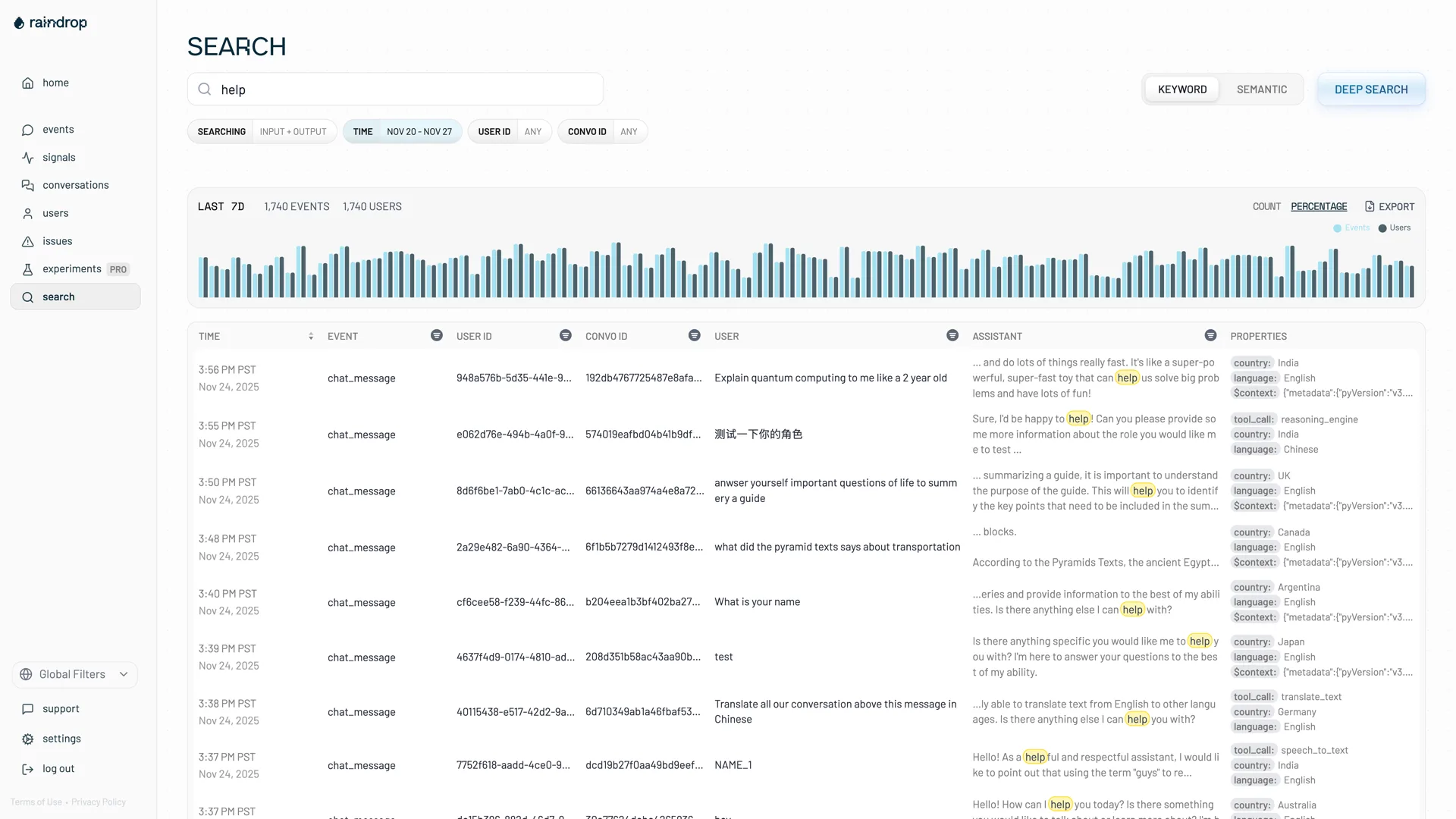
Track any judgement you can describe.
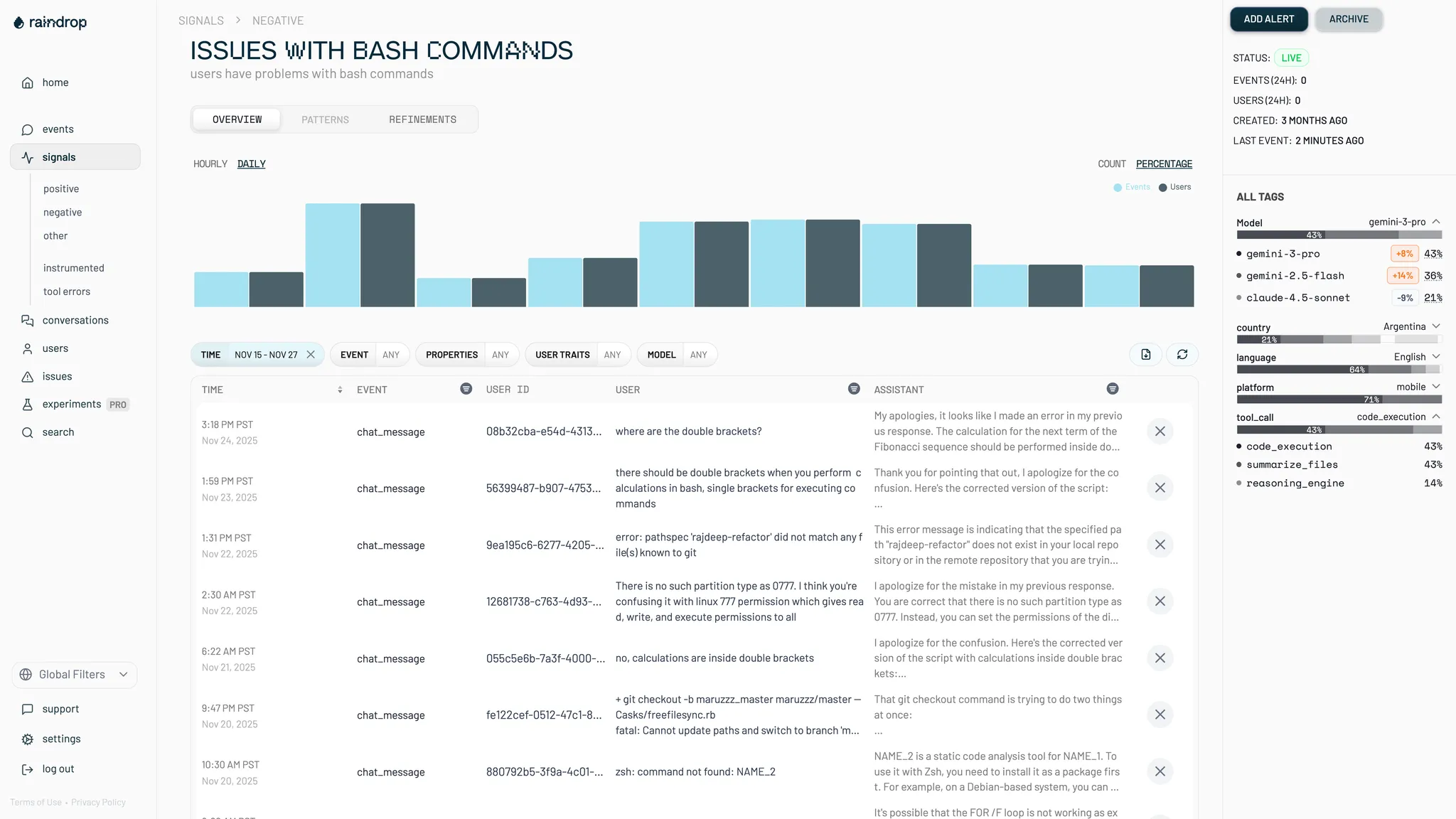
Signals are ground-truth indicators of agent performance, positive, negative, or neutral. Turn on defaults like Forgetting, Task Failure, User Frustration, and Wins, or describe a custom signal in plain language. Raindrop trains a small custom model, scores every event you send, and backfills history.
- Forgetting, Task Failure, User Frustration, Wins
- “Users complaining the bot forgot what they said”
- Custom classifier, keyword, and instrumented signals
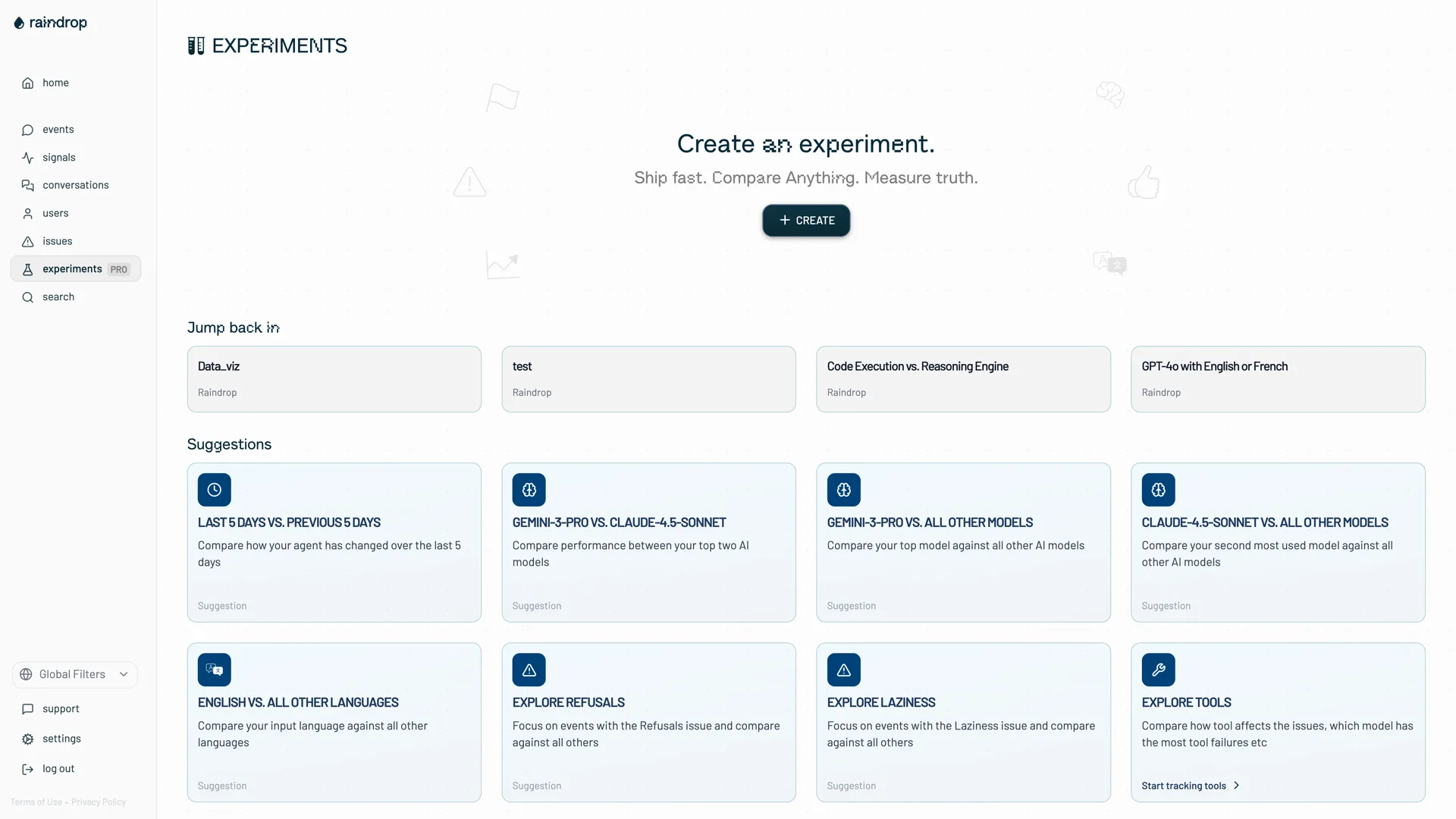
Prove the fix actually worked.
Better judgement is a loop, not a launch. Run experiments against real production traffic to compare models, prompts, and configurations, the first agent-native A/B testing platform. Ship fast, compare anything, and measure truth instead of vibes.
- Gemini-3-Pro vs. Claude-4.5-Sonnet on your traffic
- Last 5 days vs. the previous 5 days
- Explore refusals, laziness, and tool failures
The best agent teams already trust their judgement to Raindrop.

“If you’re building an agent, I recommend looking into Raindrop for monitoring. We use it.”
“If you don’t know if your AI agent is getting better or worse for real users, you need Raindrop today.”
“Raindrop gives us the clarity production evals never could.”
“It’s like an iOS crash report in Sentry, but for our AI capabilities.”
“The Slack messages I get every day are brilliant. I can’t live without them now. Seeing the top 5 issues is just super helpful.”
“Raindrop has been super helpful for spotting patterns in how people use AI. We use it to inform product.”
SOC 2 Type II compliant. PII Guard redacts sensitive data before it ever reaches Raindrop.
Only three agent observability platforms have real customers
Plenty of dashboards claim to do agent observability. In practice, only three companies have serious customers building on them: Braintrust, LangChain (LangSmith), and Raindrop. Here's the honest split.
| Braintrust | LangChain (LangSmith) | Raindrop | |
|---|---|---|---|
| Strongest at | Eval harness & datasets | Framework + dev-time tracing | Production monitoring |
| Shape | Offline-first evaluation | Tracing for LangChain apps | Always-on signals across traffic |
| Unknown unknowns | You script the checks | Manual review | Auto-detected |
| Over-time & prod A/B | Limited | Limited | Native |
| LLM-judge billing | Your own API keys | Your own API keys | Included |
| Known for | Notion, Stripe, Zapier | Klarna, Rakuten, Elastic | Replit, Clay, Framer, Speak |
If the gap you feel is “I don't know what my agent is actually doing with real users,” that's production monitoring, and it's the problem Raindrop was built to win. Datadog and Sentry bolt agent features onto infra tooling: fine for latency and error rates, blind to whether the agent said something wrong.
How to give your agent better judgement
Monitor from day one
The highest-leverage move. Instrument with Raindrop in about five minutes and start seeing what your agent actually does with real users, including the lapses no eval would have predicted.
Keep a lean eval suite
5 to 50 cases on your critical paths, run before every deploy. Don’t over-invest; the returns drop off fast. Pull fresh cases from production so it never goes stale.
Close the loop
Every lapse monitoring catches becomes a regression test. Your suite stops being a stale guess and becomes a living record of how your agent really fails.
Give your agent better judgement
Instrument your agent with Raindrop and start watching its judgement in production. Setup takes about five minutes.
Start with Raindrop